1. デジタル時代の「思い出迷子」
スマートフォンが普及し、誰もが気軽に高画質な写真や動画を撮影できるようになった現代。私たちは、数千、数万というメディアアイテムを、手元のデバイスやクラウドストレージに保存しています。私たちのデジタルライブラリは、もはや個人的なビッグデータと化しています。
しかし、この「デジタル爆発」は、新たな課題を生み出しました。それは、「思い出が多すぎて、見つけられない」という皮肉な状況です。
「去年の夏休みに行ったビーチの写真が見たい」「友達のジョンと会った3月の写真を全部見たい」—ユーザーが入力するのは、シンプルで直感的なクエリ(March 2024、Johnなど)です。しかし、数万枚のメディアの中からでは、これらのクエリは数百、数千のアイテムを返し、結局、ユーザーはスクロール地獄に陥ってしまいます。検索結果が多すぎて、本当に探している「あの瞬間」にたどり着けない、これが現在のメディア検索の限界です。
この課題を解決するために、テクノロジーはどう進化しようとしているのでしょうか。

2. 文脈を理解する提案型検索
従来の検索エンジンが「あなたが入力したキーワードに合致するものを探す」という受動的なアプローチだったのに対し、次世代の技術は「あなたが本当に探しているであろうものを見つけるために、最適な質問を提案する」という能動的なアプローチへと進化しようとしています。
例えば、以下のステップで実現されます。
2.1. メディアの「属性」特定と「テンプレート」生成
まず、ユーザーの全メディアアイテム(写真や動画)から、さまざまな「属性 (Attributes)」を特定します。属性とは、単なる日時や場所、写っている人物名だけでなく、「誕生日ケーキ」「ハイキング」「笑顔」「夕焼け」「雨の日」「ペットの犬」といった、より具体的な文脈的・意味的な情報を指します。
次に、この属性を組み合わせた「テンプレート」を大量に自動生成します。
- 例:
{人物A} + {場所B} - 例:
{イベントC} + {感情D} + {月E}
2.2. 「意味のある組み合わせ」をスコアリングで選別
生成されたテンプレートは、すべてが有用なわけではありません。そこで、システムは各テンプレートをスコアリングします。スコアリングの基準は、主に以下の二点です。
- 属性カテゴリーの多様性: テンプレートに含まれる属性の種類の多さ(日時、人物、場所、物体、行動など、多岐にわたる属性を含むほど、文脈が豊かになりスコアが高くなる)。
- メディアアイテム数: そのテンプレートに合致するメディアアイテムの数(少なすぎるとニッチすぎる、多すぎると絞り込み不足になるため、「ユーザーが適切に絞り込める数」に収まるような組み合わせが好まれる)。
このプロセスにより、「情報量が豊富で、かつ検索結果が多すぎない、ちょうど良い組み合わせ」のテンプレートが選ばれます。例えば、「2024年3月のジョンに関する写真」が多すぎたとしても、このスコアリングにより「2024年3月にジョンが写っている、公園での誕生会」といった、より有用なテンプレートが選出されます。
2.3. LLMによる「自然な言葉」への変換と提案
選ばれたテンプレート(例: [Person: John] + [Location: Park] + [Event: Birthday Party] + [Month: March 2024])は、そのままでは機械的な文字列です。ここで、大規模言語モデル(LLM)が登場します。
LLMは、このテンプレートをインプットとして受け取り、人間が日常的に使う自然な言葉(記述テキスト)に変換します。
- テンプレート:
[Person: John] + [Location: Park] + [Event: Birthday Party] + [Month: March 2024] - LLMによる出力(提案検索クエリ): 「2024年3月、公園で行われたジョンの誕生日会の写真」
この具体的で、文脈に富んだ、自然な言葉のクエリが、ユーザーインターフェース上に「提案された検索クエリ」として表示されます。ユーザーは、一からキーワードを考える必要がなく、提示された提案をタップするだけで、目的のメディアアイテム群にたどり着くことができるのです。
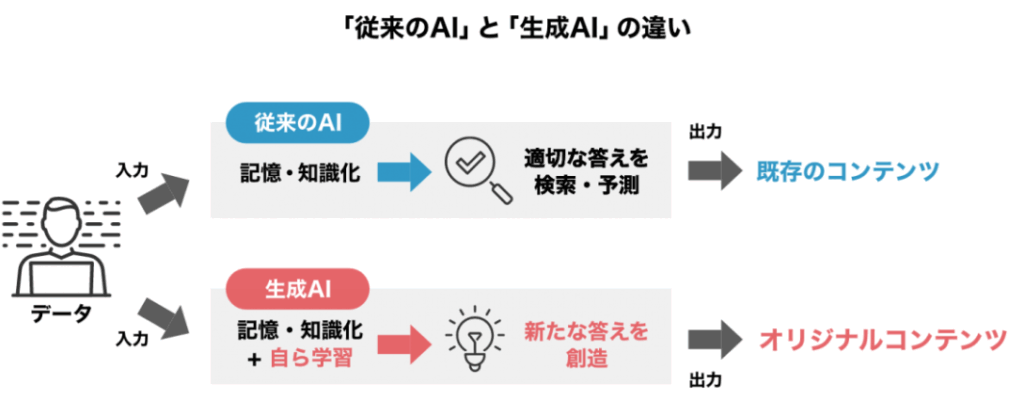
3. LLMはなぜ必要か?
なぜ、属性を組み合わせてスコアリングするだけでは不十分で、あえてLLMを導入する必要があるのでしょうか。
3.1. 検索体験の「人間化」
従来のコンピューター検索は、キーワードマッチングが基本です。しかし、人間は「キーワード」で考えるのではなく、「物語」や「文脈」で記憶しています。
LLMが導入される最大の理由は、機械的に抽出された属性の組み合わせを、ユーザーの記憶や思考に馴染む「自然な物語」へと変換するためです。
「[John] + [Park] + [Birthday]」は、単なるデータポイントの集合です。しかし、「ジョンと公園での誕生日のお祝いの瞬間」は、感情と文脈を持つ、人間的なクエリです。この変換能力こそ、人間と機械のインターフェースを劇的に改善する、LLMの真価です。
3.2. 属性抽出技術の進化
この提案型検索技術の土台となっているのは、写真・動画解析技術の進化です。
- 物体認識・シーン認識: 画像内の特定の物体(ケーキ、ビーチ、車など)やシーン(夕焼け、室内、群衆など)を認識します。
- 行動・イベント認識: 「走る」「食べる」「卒業式」「結婚式」といった、単なる物体を超えた「行動」や「イベント」を認識します。
- 感情認識: 写っている人物の表情から「笑顔」「驚き」「悲しみ」などの感情を読み取ります。
これらの高度な解析技術が、LLMに投入するための「高品質で多次元的な属性」を生み出しているのです。「属性の組み合わせ」は、この多次元的な属性を論理的かつ意味的に繋ぎ合わせる技術に他なりません。
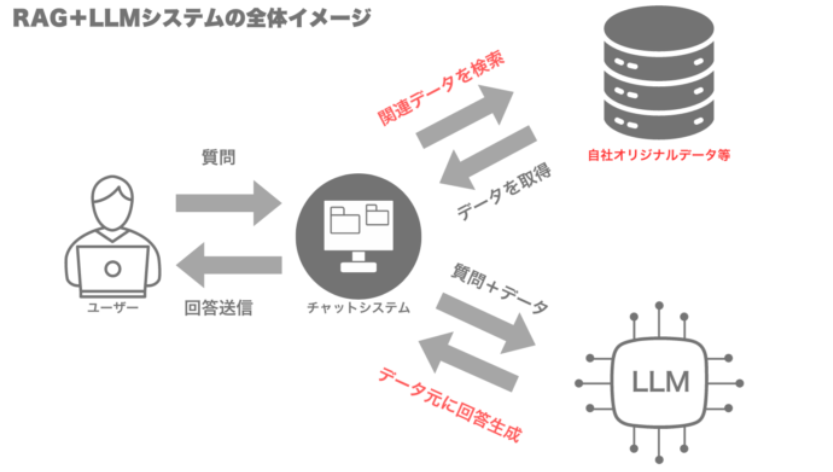
4. 未来の検索インターフェース
このLLMベースの提案型検索技術は、私たちのデジタルメディアとの関わり方を大きく変えます。
4.1. 検索の「手間」から「対話」へ
将来的には、ユーザーが検索窓に何かを入力する前に、システムが過去の行動パターンや文脈を理解し、積極的に「思い出」を提示するようになるでしょう。
- システム: 「先週の金曜日、あなたが大阪の出張先で撮った、あのおいしそうなラーメンの写真を探していますか?」
- ユーザー: 「いいえ、その前の日に見た風景写真です。」
- システム: 「承知しました。夜景と川が写っている写真ですね。これをご覧ください。」
これは、単なる検索ではなく、パーソナルな記憶アシスタントとの「対話」に近くなります。ユーザーは、あいまいな記憶をたどるだけでよく、システムがその記憶の断片を、明確な検索クエリへと補完してくれるのです。
4.2. プライバシーと倫理的な考慮事項
この技術は、個人のメディアライブラリの深い分析を伴います。そのため、プライバシーの保護は最重要課題となります。
多くの企業は、これらの高度な属性抽出やLLM処理を、可能な限りユーザーのデバイス内(ローカル)で行うことを志向しています。これにより、パーソナルで機密性の高い「属性」データがクラウドにアップロードされるリスクを最小限に抑えることが求められます。
また、抽出された属性が、人種、性別、政治的信条など、機密性の高いバイアスを含んだ情報につながらないよう、LLMの学習データと属性の定義においても、倫理的な配慮が不可欠となります。運用には常に透明性と公平性が求められます。
5. おわりに:テクノロジーが「記憶」を解き放つ
スマートフォンとクラウドストレージの普及は、私たちの「記憶の保存容量」を無限に拡張しました。しかし、記憶を「取り出す技術」が追いついていなかったため、多くの思い出がデジタルライブラリの片隅に埋もれてしまっていました。
今回の属性のスコアリングとLLMを組み合わせた提案型検索技術は、まさにこのギャップを埋めるものです。
これは、単に検索を速くする技術ではありません。テクノロジーが私たちの記憶の文脈を理解し、人間的な言葉で最も探しやすい形で差し伸べてくれる、新しい形の「記憶との再会」を可能にする技術です。
この技術の進化によって、私たちはもう「思い出迷子」になることはありません。パーソナルなデジタルメディアは、ただのデータの集合体から、いつでもアクセスできる「記憶の図書館」へと変貌を遂げるでしょう。

参考文献
- Google AI Blog (2024). How Large Language Models are Enhancing Media Search and Organization. (AIとメディア検索に関する一般的な動向を参考にしました)
- Microsoft Research Papers. Contextual Image Retrieval using multimodal inputs. (文脈的な画像検索に関する研究を参照しました)
- Apple Developer Documentation. PhotoKit and Core ML for on-device media analysis. (デバイス内でのメディア分析技術の動向を参考にしました)
📄 関連特許文献
今回のブログ記事で分析した技術(LLMを活用した提案型検索クエリ生成)に関連する、すでに公開されている特許文献をいくつかご紹介します。これらの特許は、類似の課題解決に取り組む企業の研究開発の方向性を示すものです。
| 公開番号 | 発明の名称 | 発明者/出願人 |
| US11900133B1 | Generating search suggestions for media items | Google LLC |
| US11775791B1 | Generating a set of query suggestions based on a visual feature for an image | Apple Inc. |
| US11620577B1 | Query suggestions for image search based on image features | Microsoft Technology Licensing, LLC |